Today I added some more triples to my Saxophone RDF using as "subjects" and "Objects" dbpedia. I mainly used dbpedia, because I am still not clear when to justify a website to be a good link to use for RDF. But I am working on this issue and hope to come up on a solution real soon.
Now that I have made the Saxophone RDF, I started to work on a pathway from Wikipathways to convert it into RDF. To do this I have to make use of certain predicates, that indicate certain reactions or interaction. In this case the predicates the website (http://lov.okfn.org) seems to work also really well. The next examples on how to use the "linked open vocabularies" are used from the Saxophone RDF file I made.
By going to the website you will notice a search button in the middle of the browser:
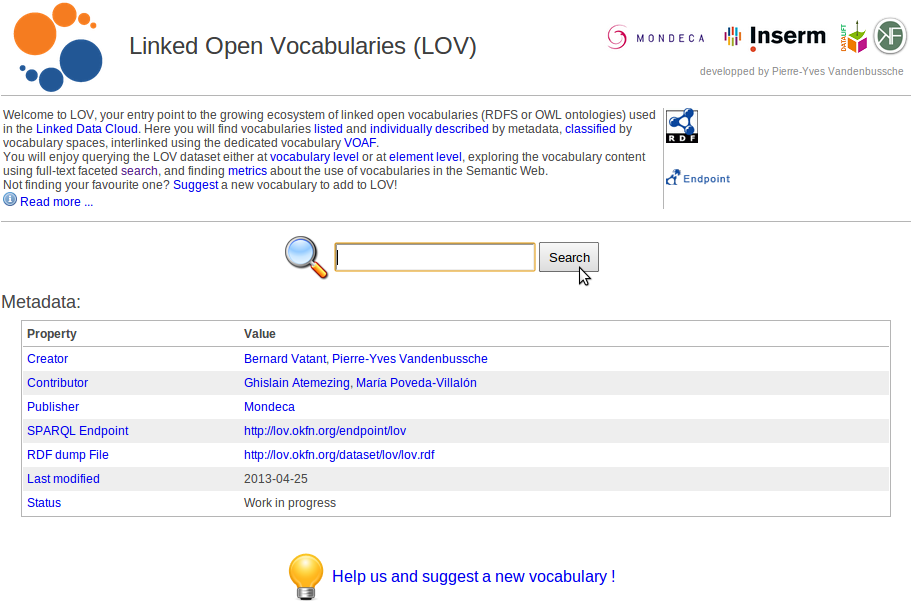
You can enter the predicate or a part of the word of the predicate you are looking for and it will try to find it. As example I will take "produced_work" from the music ontology (mo). As we type this predicate in the search area, you will instantly notice that it does NOT find any hits. This is because this search engine does not work with "_" so I had to remove it first. Second problem I stumbled up on is that you must be precise on the word or the word is a part of a bigger word to find the predicate. This mean you will find the ontology if you would look for: "produced work" or "produced" but NOT "produced works", so I have to be more strict with the naming. So I typed the words "produced work" in the search engine and luckily I fond 1 exact hit for this one:
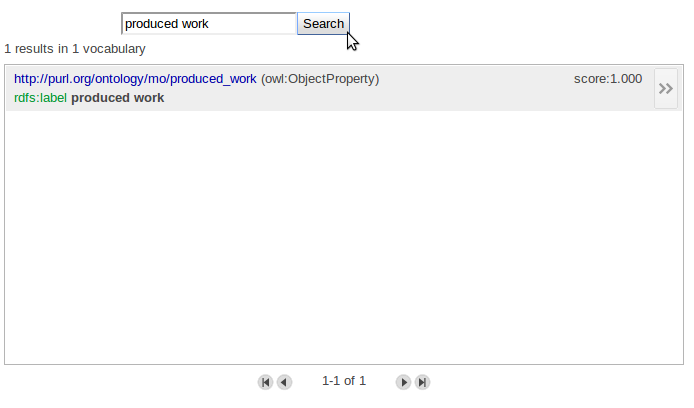
Here I copy the URI directly as the predicate. For this example we had only 1 hit but if I would look for "birth" I would get a lot of hits:
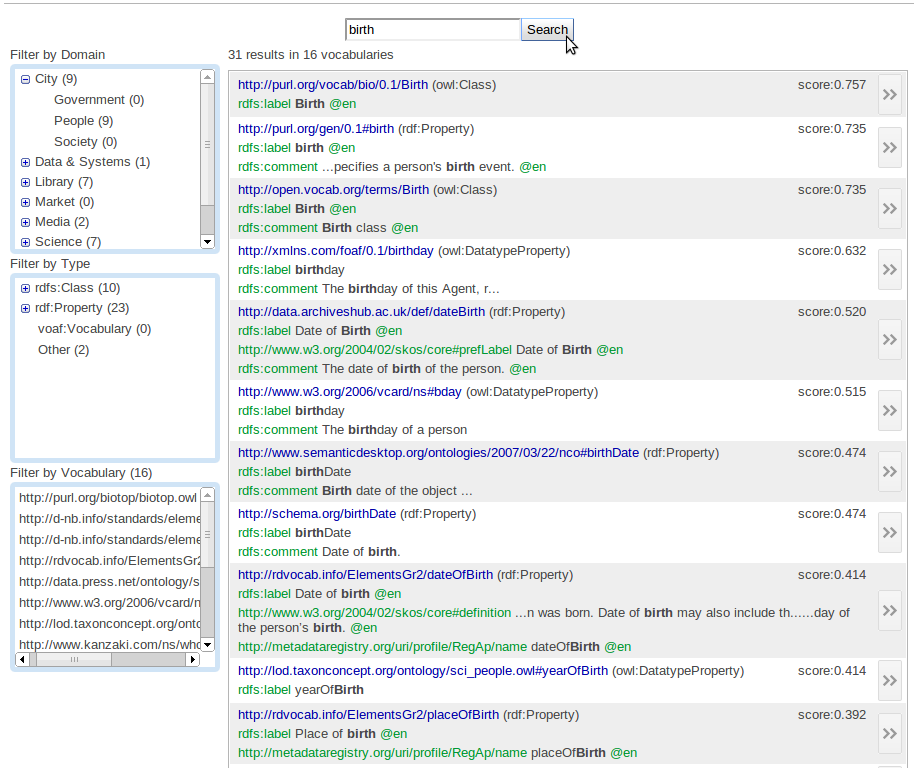
Unlike "produced work" I find a lot of hits here, but luckily there is on the left side panel a filtering possibility. These filtering steps are based on: Vocabulary, Type and Domain. So to remove most of the predicate that have no link to what I am searching for, I put the domain filter to "people". This reduced my search capacity drastically. And by using the other filers, the data output will be narrower and more specific. But still there are still some hit with "birth". In this case I pushed the arrow on the right side of the URI. This will show a pop-up with information about the URI:

As can seen in the image above, the pop-up does not only give information about the URI, it gives also some statistics between the word that was used to find the the hit and the hit. But the important information that I mainly used is the lower table ("Element information"). If this is still not enough information about the URI, it is possible to click the URI and go directly to the vocabulary in question and read more about it.
Using this website with dbpedia, I was able to make triples about the subject "Saxophone". Now that I have finished this, my next objective is to try to turn a pathway into RDF. To find the "subject" and "object" (in this case the metabolites/enzymes/proteins/genes etc.), I am using the following site that will allow me to search different vocabularies:
http://bioportal.bioontology.org/

This site was pointed out to me by my supervisor Andra Waagmeester and with the help of Egon Willighagen I was able to understand it. On this page I got the options to search all ontologies, to look for a certain ontology or to search resources. In this case I started with to search in the "search all ontologies" field for "adenosine triphosphate". This led to a list with many hits:
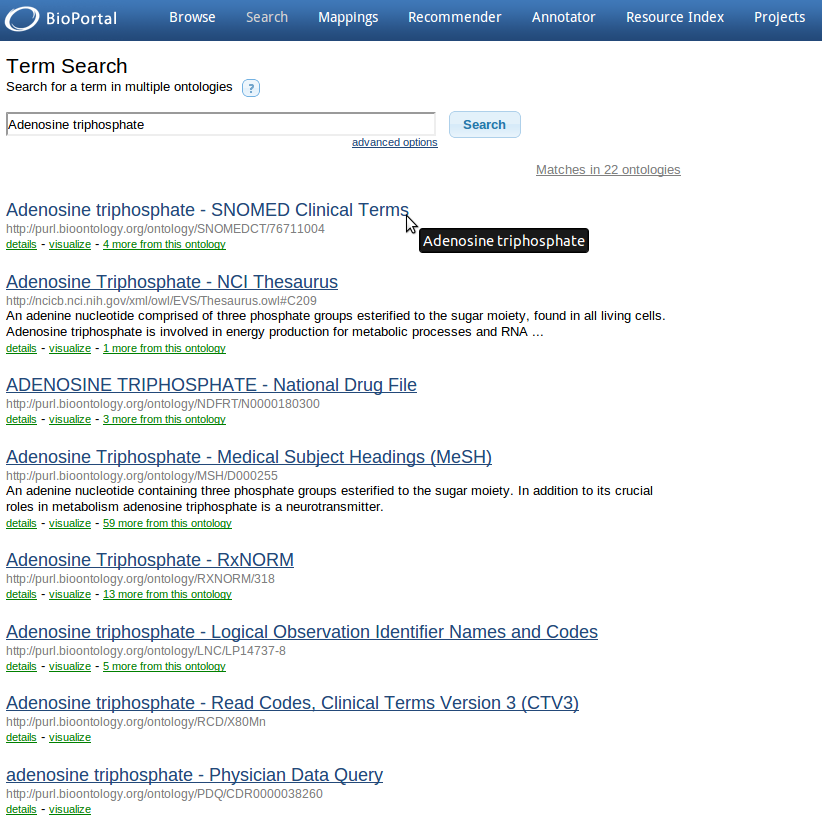
As can be seen here I found many hits with "adenosine triphosphate". To see whether the link shown has anything to do with what I am looking for, I clicked on the detail button just below each link. This will give me a pop-up with information about the link:
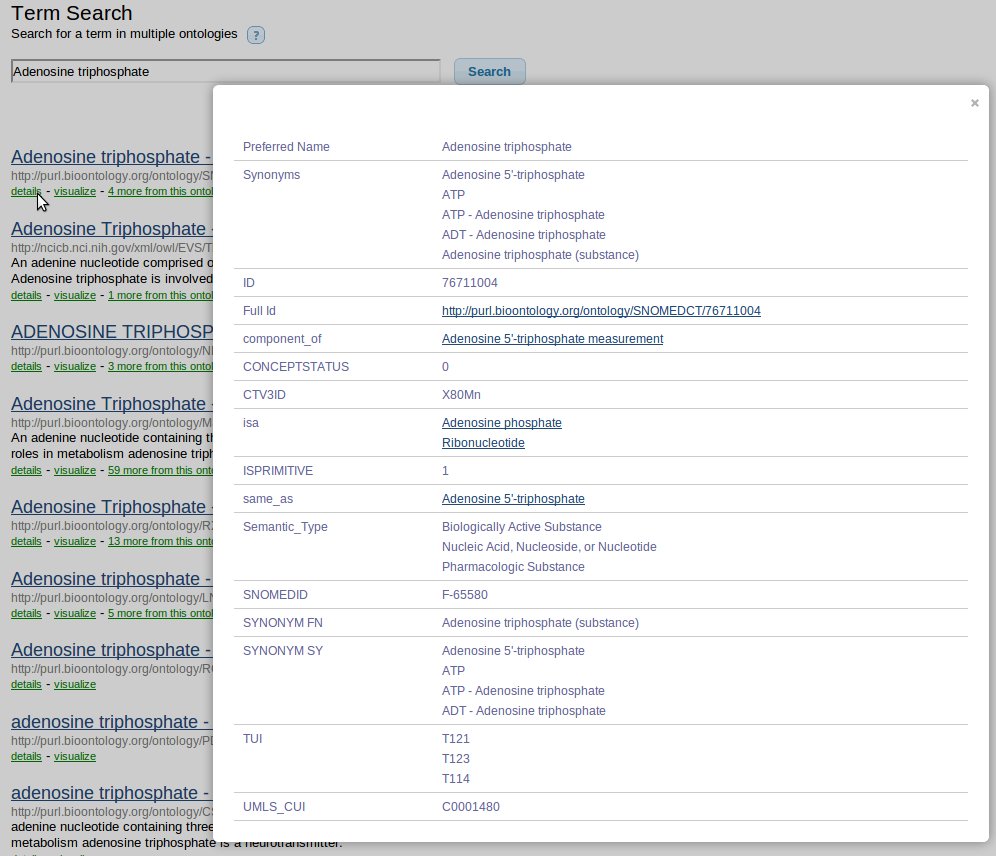
In this case it was the metabolite I was looking for, so I can use the link under the header "Full id" to put in my RDF. Using "Linked open vocabularies" to find predicates and using "bioportal NCBO" to find metabolites/enzymes/proteins/genes etc. I will try to make a RDF from a Wikipathway pathway. To start off I took a simple pathway:
http://wikipathways.org/index.php/Pathway:WP2487
This is the NAD salvage pathway II of E.coli that I uploaded on Wikipathways last week:

This is a small and relative simple pathway to convert to RDF. So This will be my goal for tomorrow to finish converting the whole pathway to RDF.
Curating Wikipathways
One of the first things I did when I started my internship to understand Wikipathways was (aside from reading the website and doing to tutorial) was try to curate existing pathways before I start building one myself.
Many of the pathways that i had to curate were Rat pathways. As example we will discuss the following pathway: Fatty Acid Beta Oxidation from Rattus norvegicus
http://wikipathways.org/index.php/Pathway:WP1307
The next pictures are examples of some of the problems I encountered during curating. I'll be also explaining how I did my curating.
First we open the pathway for editing like explained in my previous blog. Now I will can start looking for data nodes that are not annotated yet. This can be done in 3 ways:
1. You double click on the data node and see whether it is annotated.
2. You click on the data node and open on the right side panel the "Backpage" tab. This will will show whether the data node is annotated.

3. Or just scroll down the page until you reach the header "External references". Under this header every data node is noted and whether it is annotated:


As can be seen in the figure above the "Trans-Hexadecanoyl-CoA" has no reference, so we can instantly go to that metabolite and try to annotate it.
To annotate the data node I can double click on the data node type the name of the gene product and push search to find and select it (explained in more detail in previous blog). But sometimes the annotation engine of Wikipathways does not find the gene product I require. So the first thing I do, is to find out whether the removing part of the name of the gene product helps finding what I need. I do this because names can be defined differently for example: if I have a gene product called "5'-rebonucleotide" than the search engine might not recognize the "5'" so by removing it I might find that it is "5-rebonucleotide". Another reason is that its maybe misspelled and by removing a piece of the name, the search engine still be able to recognize the gene product i require.
If I still don't find the what I need, I try to find whether this is a synonym for the primary name of the specific product. And if that doesn't help maybe the product in question is wrong, and I can try to find the original reaction and see what gene products/metabolites are involved. This can be done in multiple ways:
As can be seen in the figure above the "Trans-Hexadecanoyl-CoA" has no reference, so we can instantly go to that metabolite and try to annotate it.
To annotate the data node I can double click on the data node type the name of the gene product and push search to find and select it (explained in more detail in previous blog). But sometimes the annotation engine of Wikipathways does not find the gene product I require. So the first thing I do, is to find out whether the removing part of the name of the gene product helps finding what I need. I do this because names can be defined differently for example: if I have a gene product called "5'-rebonucleotide" than the search engine might not recognize the "5'" so by removing it I might find that it is "5-rebonucleotide". Another reason is that its maybe misspelled and by removing a piece of the name, the search engine still be able to recognize the gene product i require.
If I still don't find the what I need, I try to find whether this is a synonym for the primary name of the specific product. And if that doesn't help maybe the product in question is wrong, and I can try to find the original reaction and see what gene products/metabolites are involved. This can be done in multiple ways:
- Search existing databases like: NCBI, KEGG, HMDB, ENSEMBL etc.
- Find pathways mentioned in Articles: PUBMED etc.
- Or find a book that might have the pathway noted in it.
Since "Trans-Hexadecanoyl-CoA" is a metabolite and I tried putting a part of the name in the annotation engine and didnt find anything, I am going to the HMDB website (http://www.hmdb.ca/) to look whether it is synonym and try to identify its primary name. By entering the name of metabolite of the websites search engine on top of the site:

Make sure to choose Metabolites in the "search type" field. After I pushed search, a list of metabolites are shown where this name is found. That is not only in the name of the hit, but in the synonyms list and the description list. So this means that the first hit is not necessarily the good one.

In the case the first hit is completely the same as the word searched in the search engine, but keep in mind that the origenal name had "Trans" in it, but i kept that away because I couldn't find any hit with it (this is actually the first hit that "Trans-Hexadecanoyl-CoA" is not located in this database). But I took a closer look at the first hit, but I didn't that it was the metabolite I require. But to be more sure I tried to find the complete name on google and the only hits I found were "2-Trans-Hexadecanoyl-CoA" in an article with the exact same end product as the one in Wikipathways, This can be a potential candidate to be the correct metabolite, since this is about a pigs heart mitochondria not rat, there could be a small variation. So I will try to identify this metabolite by finding an ID I can connect to it. This ID can be then inserted manually in the data node when I double click on it. But in this case I did not find enough proof and an ID to verify my findings. But these are the website I found information about it. This I can discuss with the rest of the group to come up with a definite conclusion:
http://www.genome.jp/dbget-bin/www_bget?reaction+R00385+R01278+R03776+R03856+R03989+R04753+R06985
http://www.jbc.org/content/271/30/17816.long
http://www.genome.jp/dbget-bin/www_bget?reaction+R00385+R01278+R03776+R03856+R03989+R04753+R06985
http://www.jbc.org/content/271/30/17816.long
Another problem is mistyping as i mentioned earlier. For example this metabolite: myrisoyl-CoA:

Is wrongly spelled it should be Myristoyl-CoA. Just by changing the name and looking it up on HMDB I found that is was not a primary name but the primary name was: Tetradecanoyl-CoA. Putting it in the annotation search engine I was able to annotate the metabolite:

I contineued this process untill I had annotated all the metabolites. For the ones that I could not annotate I left them as they were.
Is wrongly spelled it should be Myristoyl-CoA. Just by changing the name and looking it up on HMDB I found that is was not a primary name but the primary name was: Tetradecanoyl-CoA. Putting it in the annotation search engine I was able to annotate the metabolite:
I contineued this process untill I had annotated all the metabolites. For the ones that I could not annotate I left them as they were.
Geen opmerkingen:
Een reactie posten